Background #
June 2025: I was in the middle of my master’s thesis when, one evening while scrolling my emails, I found one about Zurich AI Safety - and first learned about this field.
One of the videos I watched early on was from Robert Miles’ Intro to AI Safety. What stuck with me was his question “What is the most important problem in you field - And why are you not working on it?” This stuck with me and I quickly felt that this was exactly, what I needed to do. But I also knew I had gaps that needed filling. I had largely neglected NLP (let’s be honest, transformers) and RL during my studies. During university, I had focused more on CNNs and later applied ML. However this also meant I wasn’t starting from zero and had most of the prerequisites of modern ML down.
Fundamentals #
The main resource I had found through Zurich AI Safety was the ARENA program. A build-first curriculum covering fundamentals, transformers, RL and LLM evaluations in four chapters (Note: They recently added even more content, which I did not have the chance to fully check out yet). ARENA was the main source I followed, though later I also found Jacob Hilton’s deep learning curriculum, which I used as additional curated collection of exercises and reading material.
And even when going through their “Fundamentals” section, I learned new things. One was einops. I had seen it in open-source replications from lucidrains before, but hadn’t invested time to understand it. The other was cross-entropy loss, which I had come across countless times, but never cared to learn where the formula originates from. Learning this fascinated me enough to write a short post on it. And for optimizers, this visual explainer is the most intuitive way I have seen this explained to date.
Transformer #
This is where I first diverged from ARENA, because I wanted to make sure, I get this. To get the context right, what helped me frame is understand what was the reason behind why this architecture happened when it happened. The article on Seq2Seq with Attention from Jay Alammar explains on how the field went from a simple encoder-decoder stack with a single state vector to per-token states and attention. Both of which are the groundwork for transformers. Once I understood the “why” it happened, what really helped me to get the “how” is starting over from a completly blank repository. And to then fill in the gaps one by one. So I read and re-read the Attention Is All You Need paper over and over again to get all the technical details down. The main thing I got away from this is a very intuitive understanding of the attention mechanism: For every token (query), look at all the keys of the tokens that came before (including the current) and take the dot product. Which is just a similarity score of the two. We softmax this to get a probability distribution and then sum up across the values (=that hold the actual content we are interested in).
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$I wanted to stay as close to the original and trained on the WMT 2014 EN-DE dataset that was used in the paper. I also used sentencepiece over the more popular (and easier to use) tiktoken library. In fact I found little to no good documentation besides a Kaparthy video - see below. I trained this on a single RTX 3090 for 32 hours.
In the end I also implemented beam search here, and noticed improvements both on single examples and on the final BLEU metric where I got similar results to the reported values in the original paper. Full implementation is on github.
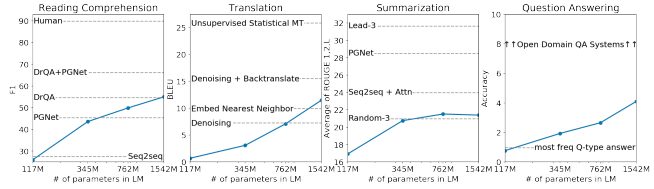
| Model | Decoding Strategy | BLEU |
|---|---|---|
| Transformer (Vaswani et al.) | Beam search | 27.30 |
| My implementation | Greedy | 26.20 |
| My implementation | Beam search | 27.45 |
Key Resources #
- Attention Is All You Need (Vaswani, 2017) - great paper, also easy to follow / well written
- Jay Alammar — Seq2Seq with Attention - as mentioned, really valuable to get the context
- Jay Alammar — The Illustrated Transformer - nicely illustrated if stuck, simple explanations
- Łukasz Kaiser — Transformer talk — watched the whole thing, Łukasz is one of the authors and a great speaker imo
- Andrej Karpathy — tokenization - the only real explanation/tutorial of sentencepiece I was able to find
Some more thoughts regarding these resources. They are great, but some of them are also traps. E.g. The Illustrated Transformer to me did never really 100% click until I implemented it from scratch. And I looked at this article before every ML exam in uni. Doing stuff >>> reading about other people doing stuff.
GPT #
After having a working Transformer, the natural next step was to see how we go from this to LLMs. Because before ChatGPT, there were GPT-1, 2 and 3. Reading through these three papers, it’s not really about the architecture. Decoder-only at a basic level is even simpler than the Encoder-Decoder from Attention Is All You Need. It’s already visible here that it’s now mostly about training regime and scale.
Again, I wanted to get it, so also started over and build GPT-2 from scratch. Architecture wise there were not many changes needed. To actually train it, and make it more efficient I borrowed a couple of tricks that Kaparthy’s Let’s reproduce GPT-2 (124M) highlights. The main one being to use the 10B sample of the FineWeb-Edu dataset. Also to use torch.compile, mixed precision and FlashAttention.
But the biggest learning from this project came from a subtle bug I introduced. In the GPT-2 paper, they mention that LayerNorm was moved to the input of each sub-block. In my initial implementation, I wrote this:
def forward(self, x):
x = self.ln1(x)
sub1 = self.self_attention(x)
...
x = x + sub1
which makes the information exchange via the residual stream harder than it should be and leads to worse results. My intuition regarding the residual stream is from the Mathematical Framework for Transformer Circuits. In the end I evaluated my implementation on HellaSwag. It was worse, but still in a similar ballpark as the GPT-2 checkpoint I used to compare against (training took around a day on a RTX 4090):
| Model | HellaSwag Accuracy |
|---|---|
| Original GPT-2 small | 31.45% |
| My implementation | 29.82% |
Key Resources #
- GPT-1 (Radford, 2018) - short & easy to grasp
- GPT-2 (Radford, 2019) - again short, and highlights the big ideas to come already
- GPT-3 (Brown, 2020) - way longer than the previous two, mainly used Section B for concrete training hyperparameters since GPT-2 is vague about them
- Karpathy — Let’s reproduce GPT-2 (124M) - useful resource if stuck (also his other videos)
- Mathematical Framework for Transformer Circuits (Anthropic) - the residual stream framing
- Scaling Laws (Kaplan, 2020) - what’s happening in the world today
- Chinchilla (Hoffmann, 2022) - how to train a compute optimal model
- FlashAttention (Dao, 2022) - it’s the default now
- Online softmax (Milakov & Gimelshein, 2018) - pre-req for flash attention
- Llama 3 paper - probably the most complete account of how modern LLMs are actually trained
- Lecture: How Modern LLMs Are Built - nice summary of all, first time i see the flops formula explained (6 × n_tokens × params)
Mechanistic Interpretability #
This is also were I started reading more of the Transformer Circuits Thread. For me, the most influential articles here are the earlier works. Largely because they lay the foundation of understanding that one should have. One, A Mathematical Framework for Transformer Circuits, which brings up the residual stream and how information processing works in the transformer via QK and OV circuits. Two, In-Context Learning and Induction Heads that showcases that these circuits are capabilities learned in the training regime - and we can even pinpoint at what point they happen. Toy Models of Superposition why mech interp can be so difficult in practice. Also a shoutout to the original Distill circuits work on InceptionV1. This is real beautiful work and I’d be excited to explore CNNs more at one point like Liv Gordon did in her The Missing Curve Detectors of InceptionV1.
With Chapter 1 from ARENA I went into TransformerLens and adjacent SAE work. The chapter first introduced induction heads in a small 2-layer attention-only transformer, where the circuit is clean enough to inspect directly, and then had us apply the same TransformerLens tools to GPT-2 small. This was useful to get an understanding of common techniques such as the activation cache, hooks or activation and path patching.
Then the SAE material reframed this from “inspect heads and MLPs directly” to “learn a sparse feature basis over activations and interpret the model through that basis”. In practice this meant working with SAELens / Neuronpedia-style workflows: loading pretrained SAEs, looking at feature dashboards, doing logit attribution and ablations, and thinking about phenomena like feature splitting and feature absorption.
From my point of view, the field has moved on though from looking at SAEs as the interp solution. First, GDM & Neel Nanda heavily updated towards pragmatic interp and linear probe work and showcased why in Negative Results for SAEs On Downstream Tasks and Deprioritising SAE Research. Second, I saw recent works on Activation Oracles (this has already been added to the new ARENA material!) which I find super promising. Especially (edit April 20) from the Mythos system card, in an unsupervised setting the Activation Verbalizers.
Key Resources #
- A Mathematical Framework for Transformer Circuits - residual stream, QK/OV circuits, attention heads as information-moving operations
- In-Context Learning and Induction Heads - canonical induction-head work and training-time phase transition
- Toy Models of Superposition - why features can be represented non-orthogonally and why interpretability is hard
- Negative Results for SAEs On Downstream Tasks and Deprioritising SAE Research - important pragmatic update: SAEs underperformed linear probes on OOD harmful-intent probing
- Activation Oracles - newer activation-to-language direction, useful as an auditing and hypothesis-generation tool
- Distill Circuits Thread - beautiful earlier vision/circuits work and useful context for the transformer-circuits style
RL #
I think RL is absolutely beautiful - and I rewatch the AlphaGo Documentary every year. I also think it’s pretty hard to wrap your head around. Somewhat. But anything can be done with enough motivation, and my motivation hereby was RLHF. To be fair, also here I didn’t start from scratch. I had already covered the basics such as MDPs, Bellman equations, TD Learning and DQN throughout university. So it was pretty easy for me to follow the first half of the ARENA Chapter 2, which goes through exactly that. PPO was new for me. I followed ARENA here too, but after going working on this chapter, I was still confused.
So I again decided to start from a blank state and reimplement from scratch, rather than filling out the already pre-made skeleton-code in their notebooks. Which is also the exercise in RL chapter in Jacob Hilton’s curriculum.

The full implementation from me is as before on github. What really helped here was to get all the details right. Because this was for me the difference between the agent learning, and just getting stuck early. These PPO implementation details helped a lot to grasp these details and this one how to debug RL surfaced bugs quickly.
The last piece missing is then RLHF (ARENA_2.4). We take our pretrained LM, collect human preference data, train a reward model on those preferences - often the reward model is of similar size than the LM, and can be the same, just with a different head, and fine-tune the language model with RL against that reward model. So the model learns to mimic what human (labeller)s want.
ARENA 2.4 has you actually implement this end-to-end on a small LM. The reward function we used was “maximize the number of periods in the output” - without a KL coefficient against the original model, the policy just collapses completely and spams …….. With the KL term on it gets way more interesting: the model shifts towards shorter sentences, text full of URLs, and abbreviations like “U.S.” or “Ph.D.” appearing a lot more than they should. The reward hacking now has to happen within the original distribution.
Key Resources #
Basics: #
- Amazing high quality RL youtube series (1, 2, 3, 4) (follows Sutton & Barto)
- DQN (Mnih, 2015) - deep RL via Q-learning, the replay buffer + target network paper
- Sutton & Barto — RL textbook - the RL bible, targeted reading
- DeepMind × UCL RL lecture series - as additional input if something was hard to grasp
PPO Implementation + Literature: #
- PPO (Schulman, 2017) - the main paper
- What Matters in On-Policy RL (Andrychowicz, 2020) - interesting read, shows it’s the details that make PPO work (better)
- PPO implementation details - borderline impossible to get all the details correct without this
- Debugging RL (andyljones) - probe environments to surface bugs
- OpenAI Five (Dota 2) - PPO at massive scale
- GRPO / DeepSeekMath (Shao, 2024) - DeepSeek pioneered default nowdays
RLHF #
- HuggingFace — RLHF blog - clean overview
- Deep RL from Human Preferences (Christiano, 2017) - started RLHF
- InstructGPT (Ouyang, 2022) - RLHF applied to LLMs
LLM Evals #
In ARENA Chapter 3 I worked through LLM evals using Inspect. In Inspect, an eval is organized as a Task: a dataset defines the samples, a Solver defines how the model is called or scaffolded, and a Scorer evaluates the final output or trajectory. I found this way more interesting than I expected, because it felt much closer to experimental design than I thought.
ARENA uses alignment faking as the motivating case study here. The workflow is to define the threat model, build the scaffold, run the model, inspect transcripts, revise the setup, and be honest about what the result does or does not imply. This is the part I liked most: the implementation matters, but the harder part is often deciding whether your setup actually measures the thing you claim it measures.
This also made me more sensitive to bad eval design. If you heavily steer the model into a behavior, or basically system-prompt it to act misaligned, then the result mostly tells you that the model followed the experimental setup. That can still be useful for studying a model organism or a specific failure mode, but it is different from showing that the deployed model has that propensity by default. Good evals need to be clear about this distinction: what behavior is being elicited, what assumptions the scaffold introduces, and what conclusion the result can actually support.
Key Resources #
- A starter guide for evals - good conceptual overview from Apollo Research
- We need a Science of Evals - why eval methodology itself needs rigor
- Alignment faking in large language models - concrete case study of an alignment eval that ARENA also builds around
- Petri - automated multi-turn alignment auditing
- Investigating models for misalignment - UK AISI example of realistic alignment evaluation scaffolding
- Sidestepping Evaluation Awareness with Production Evaluations - production-like evals as a realism strategy
- Evaluating Frontier Models for Dangerous Capabilities - GDM dangerous-capability eval suite
- Evaluating Frontier Models for Stealth and Situational Awareness - scheming-relevant eval design and safety-case framing
Next Steps #
As for my next steps, I now feel I’m ready to start keeping up with SOTA across the different subfields in safety. I have started reading Twitter, various company research science blogs (especially Anthropic and OAI), and follow new work as it comes out - rather than catch up. Also, I have been advised by people whose opinion I value, that I need to get out and build things myself rather than just re-implementing. So will start doing this more too.